Presentation¶
The N2D2 platform is a comprehensive solution for fast and accurate Deep Neural Network (DNN) simulation and full and automated DNN-based applications building. The platform integrates database construction, data pre-processing, network building, benchmarking and hardware export to various targets. It is particularly useful for DNN design and exploration, allowing simple and fast prototyping of DNN with different topologies. It is possible to define and learn multiple network topology variations and compare the performances (in terms of recognition rate and computationnal cost) automatically. Export targets include CPU, DSP and GPU with OpenMP, OpenCL, Cuda, cuDNN and TensorRT programming models as well as custom hardware IP code generation with High-Level Synthesis for FPGA and dedicated configurable DNN accelerator IP 1.
In the following, the first section describes the database handling capabilities of the tool, which can automatically generate learning, validation and testing data sets from any hand made database (for example from simple files directories). The second section briefly describes the data pre-processing capabilites built-in the tool, which does not require any external pre-processing step and can handle many data transformation, normalization and augmentation (for example using elastic distortion to improve the learning). The third section show an example of DNN building using a simple INI text configuration file. The fourth section show some examples of metrics obtained after the learning and testing to evaluate the performances of the learned DNN. Next, the fifth section introduces the DNN hardware export capabilities of the toolflow, which can automatically generate ready to use code for various targets such as embedded GPUs or full custom dedicated FPGA IP. Finally, we conclude by summarising the main features of the tool.
Database handling¶
The tool integrates everything needed to handle custom or hand made databases:
Genericity: load image and sound, 1D, 2D or 3D data;
Associate a label for each data point (useful for scene labeling for example) or a single label to each data file (one object/class per image for example), 1D or 2D labels;
Advanced Region of Interest (ROI) handling:
Support arbitrary ROI shapes (circular, rectangular, polygonal or pixelwise defined);
Convert ROIs to data point (pixelwise) labels;
Extract one or multiple ROIs from an initial dataset to create as many corresponding additional data to feed the DNN;
Native support of file directory-based databases, where each sub-directory represents a different label. Most used image file formats are supported (JPEG, PNG, PGM…);
Possibility to add custom datafile format in the tool without any change in the code base;
Automatic random partitionning of the database into learning, validation and testing sets.
Data pre-processing¶
Data pre-processing, such as image rescaling, normalization, filtering… is directly integrated into the toolflow, with no need for external tool or pre-processing. Each pre-processing step is called a transformation.
The full sequence of transformations can be specified easily in a INI text configuration file. For example:
; First step: convert the image to grayscale
[env.Transformation-1]
Type=ChannelExtractionTransformation
CSChannel=Gray
; Second step: rescale the image to a 29x29 size
[env.Transformation-2]
Type=RescaleTransformation
Width=29
Height=29
; Third step: apply histogram equalization to the image
[env.Transformation-3]
Type=EqualizeTransformation
; Fourth step (only during learning): apply random elastic distortions to the images to extent the learning set
[env.OnTheFlyTransformation]
Type=DistortionTransformation
ApplyTo=LearnOnly
ElasticGaussianSize=21
ElasticSigma=6.0
ElasticScaling=20.0
Scaling=15.0
Rotation=15.0
Example of pre-processing transformations built-in in the tool are:
Image color space change and color channel extraction;
Elastic distortion;
Histogram equalization (including CLAHE);
Convolutional filtering of the image with custom or pre-defined kernels (Gaussian, Gabor…);
(Random) image flipping;
(Random) extraction of fixed-size slices in a given label (for multi-label images)
Normalization;
Rescaling, padding/cropping, triming;
Image data range clipping;
(Random) extraction of fixed-size slices.
Deep network building¶
The building of a deep network is straightforward and can be done withing the same INI configuration file. Several layer types are available: convolutional, pooling, fully connected, Radial-basis function (RBF) and softmax. The tool is highly modular and new layer types can be added without any change in the code base. Parameters of each layer type are modifiable, for example for the convolutional layer, one can specify the size of the convolution kernels, the stride, the number of kernels per input map and the learning parameters (learning rate, initial weights value…). For the learning, the data dynamic can be chosen between 16 bits (with NVIDIA cuDNN 2), 32 bit and 64 bit floating point numbers.
The following example, which will serve as the use case for the rest of this presentation, shows how to build a DNN with 5 layers: one convolution layer, followed by one MAX pooling layer, followed by two fully connected layers and a softmax output layer.
; Specify the input data format
[env]
SizeX=24
SizeY=24
BatchSize=12
; First layer: convolutional with 3x3 kernels
[conv1]
Input=env
Type=Conv
KernelWidth=3
KernelHeight=3
NbOutputs=32
Stride=1
; Second layer: MAX pooling with pooling area 2x2
[pool1]
Input=conv1
Type=Pool
Pooling=Max
PoolWidth=2
PoolHeight=2
NbOutputs=32
Stride=2
Mapping.Size=1 ; one to one connection between convolution output maps and pooling input maps
; Third layer: fully connected layer with 60 neurons
[fc1]
Input=pool1
Type=Fc
NbOutputs=60
; Fourth layer: fully connected with 10 neurons
[fc2]
Input=fc1
Type=Fc
NbOutputs=10
; Final layer: softmax
[softmax]
Input=fc2
Type=Softmax
NbOutputs=10
WithLoss=1
[softmax.Target]
TargetValue=1.0
DefaultValue=0.0
The resulting DNN is shown in figure [fig:DNNExample].
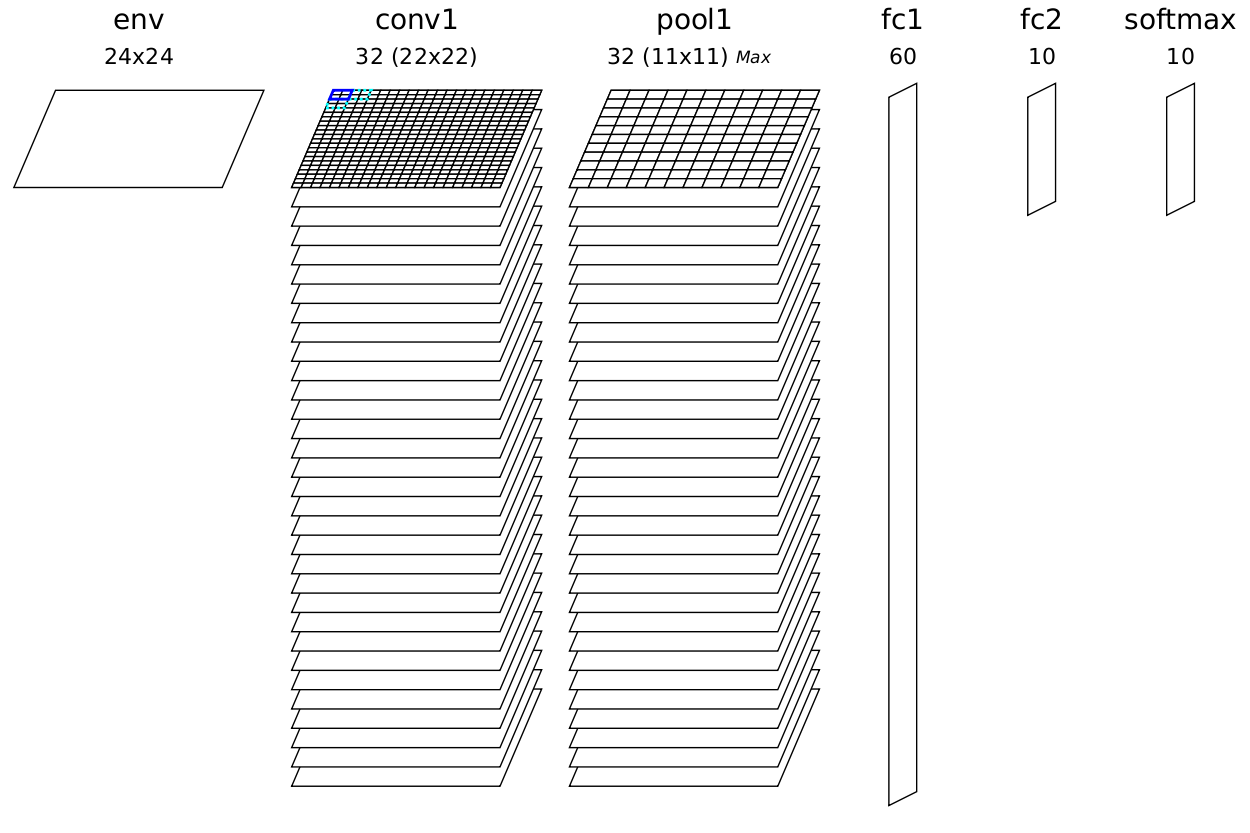
Automatically generated and ready to learn DNN from the INI configuration file example.¶
The learning is accelerated in GPU using the NVIDIA cuDNN framework, integrated into the toolflow. Using GPU acceleration, learning times can be reduced typically by two orders of magnitude, enabling the learning of large databases within tens of minutes to a few hours instead of several days or weeks for non-GPU accelerated learning.
Performances evaluation¶
The software automatically outputs all the information needed for the network applicative performances analysis, such as the recognition rate and the validation score during the learning; the confusion matrix during learning, validation and test; the memory and computation requirements of the network; the output maps activity for each layer, and so on, as shown in figure [fig:metrics].
Hardware exports¶
Once the learned DNN recognition rate performances are satisfying, an optimized version of the network can be automatically exported for various embedded targets. An automated network computation performances benchmarking can also be performed among different targets.
The following targets are currently supported by the toolflow:
Plain C code (no dynamic memory allocation, no floating point processing);
C code accelerated with OpenMP;
C code tailored for High-Level Synthesis (HLS) with Xilinx Vivado HLS;
Direct synthesis to FPGA, with timing and utilization after routing;
Possibility to constrain the maximum number of clock cycles desired to compute the whole network;
FPGA utilization vs number of clock cycle trade-off analysis;
OpenCL code optimized for either CPU/DSP or GPU;
Cuda kernels, cuDNN and TensorRT code optimized for NVIDIA GPUs.
Different automated optimizations are embedded in the exports:
DNN weights and signal data precision reduction (down to 8 bit integers or less for custom FPGA IPs);
Non-linear network activation functions approximations;
Different weights discretization methods.
The exports are generated automatically and come with a Makefile and a working testbench, including the pre-processed testing dataset. Once generated, the testbench is ready to be compiled and executed on the target platform. The applicative performance (recognition rate) as well as the computing time per input data can then be directly mesured by the testbench.
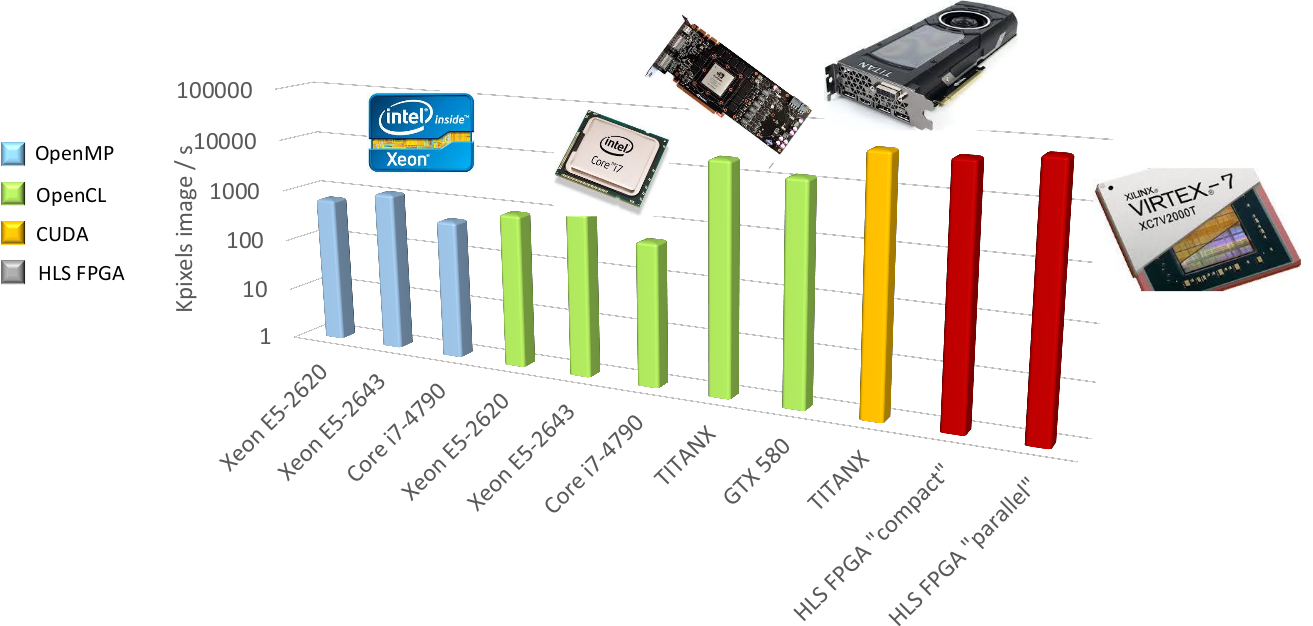
Example of network benchmarking on different hardware targets.¶
The figure [fig:TargetsBenchmarking] shows an example of benchmarking results of the previous DNN on different targets (in log scale). Compared to desktop CPUs, the number of input image pixels processed per second is more than one order of magnitude higher with GPUsand at least two orders of magnitude better with synthesized DNN on FPGA.
Summary¶
The N2D2 platform is today a complete and production ready neural network building tool, which does not require advanced knownledges in deep learning to be used. It is tailored for fast neural network applications generation and porting with minimum overhead in terms of database creation and management, data pre-processing, networks configuration and optimized code generation, which can save months of manual porting and verification effort to a single automated step in the tool.